这道题的总体思路还是比较清晰的,没有搞一些乱七八糟的东西来混淆我们,它就是用三个函数对输入的 flag 进行加密之后,再和 byte_602080 对比
# 主函数
1 | __int64 __fastcall main(int a1, char **a2, char **a3) |
这个数组的值已经给出来了
1 | [0x5A, 0x60, 0x54, 0x7A, 0x7A, 0x54, 0x72, 0x44, 0x7C, 0x66, |
接下来就看三个函数分别做了些什么吧
# sub_4006B6 函数
1 | bool __fastcall sub_4006B6(_DWORD *a1, __int64 a2, int a3) |
这里很明显可以看出就是 RC4 加密,这里是在创建 S 盒,并且进行了一部分的置换
# sub_4007DB 函数
1 | _DWORD *__fastcall sub_4007DB(_DWORD *a1, __int64 a2, int a3) |
这里是 RC4 加密的后一部分,再进行了最后的 S 盒的置换后,用新的 S 盒和我们输入的 flag 进行异或运算,得到加密后的结果,这里 v9 就是最后的 S 盒,a2 是 flag
# sub_4008FA 函数
1 | _DWORD *__fastcall sub_4008FA(__int64 a1, int a2, const char *a3, _DWORD *a4) |
这个函数很像 base64,因为它在 43~48 行有一个三字节变四字节的操作,不过又不是完整的 base64,感觉也不像是换表的操作,根本没有找到表,所以最后还是直接逆运算搞出来了
# 整体思路
前两个函数是 RC4 加密,具体的 v9 值可以动调提取数据
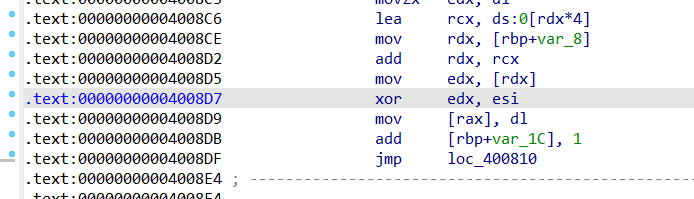
通过汇编代码可以看出来这个 v9 的值应该就是 edx 里面的值了,esi 是输入的值,动调的时候直接在 xor 这里下个断点就可以看了,下面是 v9 的值也就是最后的 S 盒
1 | [0x10, 0x59, 0x9C, 0x92, 0x06, 0x22, 0xCF, 0xA5, 0x72, 0x1E, |
在输入的 flag 和这个 v9 异或之后,又在第三个函数中将其 3 变 4,并有一点点的运算在里面,这个我们直接拿最后的结果反向算一遍就可以了

其中 v13,v14,v8 也就是 v15,分别是原来的三个字节,而在这里它被改变成了 a3 [v16] 到 a3 [v16+3] 相当于四个字节,所以原来的三个字节就是前两个函数加密后的结果,我们只要把它四个四个一组恢复成三字节就行了,还要注意一下这个位移和与运算的关系,v14 和 v15 放到一起的时候要把 0x3F 拆开,不然 flag 会不完整
# 脚本
1 | a = [0x5A, 0x60, 0x54, 0x7A, 0x7A, 0x54, 0x72, 0x44, 0x7C, 0x66, |
我这个脚本有点 bug,输出的结果前面会有一串乱码,但是结果是对的
得到 flag {e10adc3949ba59abbe56e057f20f883e}